

Asst. Prof. Junchen Jiang Receives Google Award to Improve Streams for Machines
Most streaming video services are, naturally, designed for human viewers. Netflix, YouTube, and their peers design systems that maximize video quality with minimal buffering given bandwidth constraints. But what if the consumer of a video stream isn’t a human watching a movie, but a neural network trying to make sense of a street camera feed, or the camera on a self-driving car?
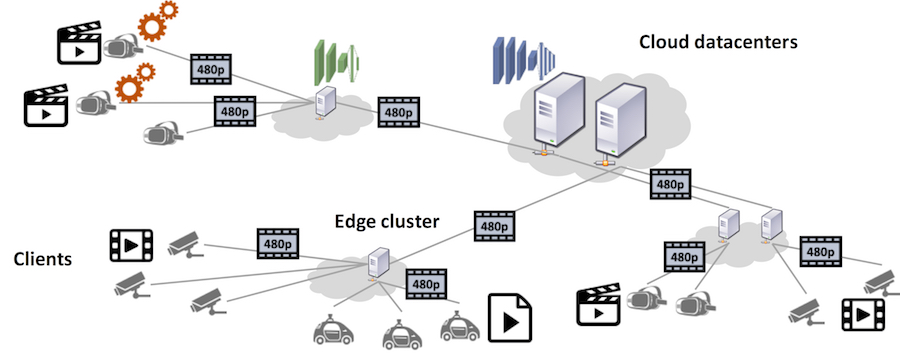
The different streaming needs of humans and machines underlies the proposal that won Assistant Professor Junchen Jiang a Google Faculty Research Award, announced by the tech company last month. Jiang’s proposal, “Scaling Deep Video Analytics to the Edge,” seeks to exploit the very particular needs of machine learning algorithms to push these technologies closer to the source of the data and realize some of the promised benefits of real-time computer vision. The effort is part of a broader research project in which Jiang and Andrew Chien, William Eckhardt Distinguished Service Professor of Computer Science, re-design the application architectures to scale a variety of intelligent applications, including video analytics, to millions of edge devices.
Currently, the deep neural networks with the best performance on computer visions tasks such as image recognition or event detection must be run on powerful resources, typically in massive data centers. Video sensors usually send their data back to one of these centers for processing, which presents problems of data storage, transmission, and the latency with which the data can be used to make decisions — ideally, a self-driving car wouldn’t want to ask the cloud every time if a traffic light is green or red.
The scientific challenge then is to move more of these machine learning process “to the edge,” allowing data analysis to happen inside the sensor, with results used immediately for decision-making or delivered back to a central server in condensed form. Because there’s still a gap between the computing power available on edge devices and what’s need to run advanced video analytics, Jiang’s project will combine networked systems and machine learning to create shortcuts.
One approach rethinks how data is delivered from a camera to a computer. Many video applications are a one-way street for this task — they’re designed to deliver a movie or a livestream from the source to the viewer, with no feedback. But machine learning models can talk back to the video source, telling the sensor what specific information it needs to recognize objects or make decisions. Jiang proposes a system where a conversation between the camera and the neural network improves the efficiency of analysis, with the neural network asking for higher-resolution images only when necessary, or requesting only a portion of the full image.
“Suppose we stream a video from a camera to a remote model, we can first send the video in low quality level and then, depending on where the server needs more data, we can ‘zoom-in’ on certain spatial regions or temporal segments with a higher quality level,” Jiang said.
Another idea in the proposal would improve edge analytics by chopping up neural networks into customizable building blocks. Today’s deep neural networks are typically very large models capable of analyzing many different components of an image to classify a wide array of objects. Jiang proposes creating smaller “micro-scale” DNNs that are specialized for identifying particular objects of interest, such as cars or pedestrians for a traffic camera, that will be able to run on the limited computing power of edge devices. Ideally, these micro DNNs can be recombined and updated on the fly by the central server as objectives change; for example, swapping out a “bicycle” model for a “snow plow” model in winter months.
Through its self-driving car and general AI research, Google is highly interested in new approaches that will improve video analytics, and Jiang said he is excited to work with the company on the project.










